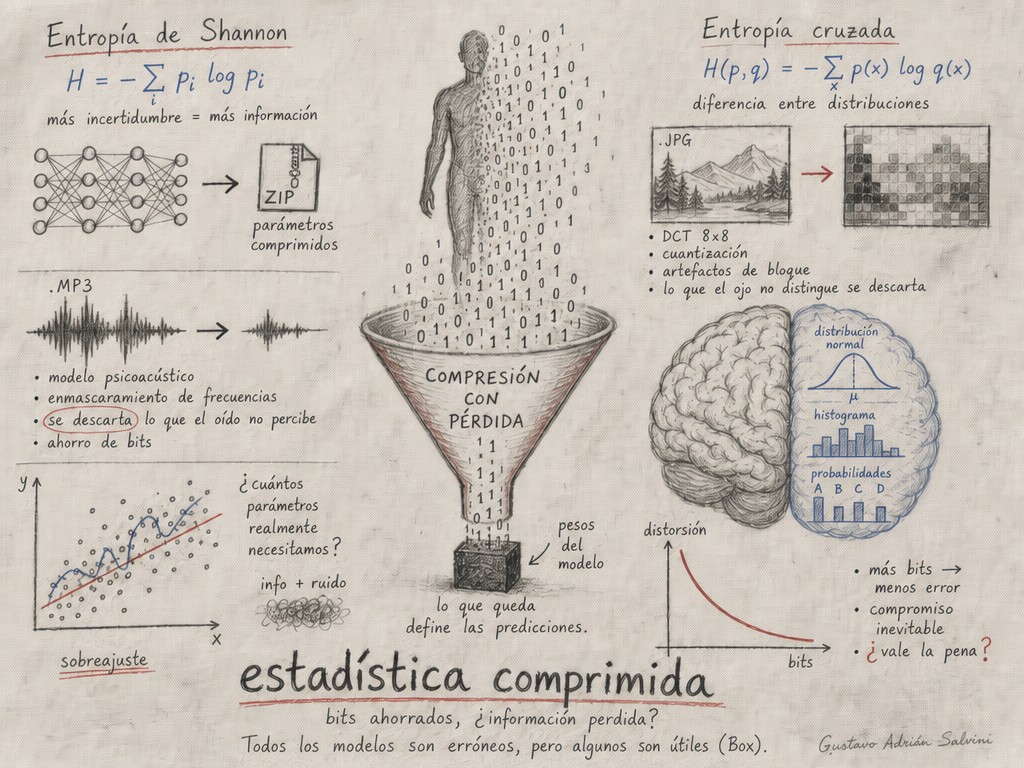
Redes neuronales como sistemas de compresión con pérdida — Photo: Gustavo Adrián Salvini
Un modelo entrenado no es inteligencia: es un archivo comprimido del mundo en que fue entrenado.
Table of contents
Open Table of contents
La tesis
Imaginá que tenés un millón de canciones en formato WAV, lo que equivale a unos 5 terabytes de datos. Las pasás por un codificador MP3 a 128 kbps y obtenés unos 400 gigabytes. Después, repetí el proceso: tomás esas 400 canciones comprimidas y las volvés a pasar por MP3, una y otra vez. Eventualmente, lo que queda no se parece a música.
Ahora imaginá algo diferente: tomás el mismo millón de canciones, pero en vez de comprimirlas con un algoritmo diseñado por humanos, construís un sistema que las escucha durante semanas, aprendiendo qué nota suele seguir a qué otra, qué progresiones armónicas son típicas, qué timbres caracterizan a cada instrumento. Al final, el sistema no guarda las canciones: guarda lo que aprendió sobre la música. Un puñado de números -digamos, 7 mil millones de parámetros flotantes, unos 14 GB en FP16- que capturan la esencia estadística de esas canciones.
Ese sistema es una red neuronal. Los 14 GB de pesos flotantes no contienen copias de las canciones como lo haría un archivo comprimido: codifican una función de probabilidad condicional entrenada para predecir secuencias a partir de los patrones de los datos. Eso es comprimir información con pérdida en el sentido más directo del término.
La equivalencia entre entrenar una red neuronal y comprimir datos está establecida en la teoría de la información de Claude Shannon: la función de pérdida con la que se entrenan los modelos -la entropía cruzada- mide directamente cuántos bits por token necesitarías para codificar los datos usando el modelo como predictor. Y en 2023, DeepMind lo verificó experimentalmente: un modelo de lenguaje de 70 mil millones de parámetros -el mismo que se usa para conversar- comprime imágenes mejor que PNG y audio mejor que FLAC.
Mi intención al escribir este artículo es llevar esa idea hasta el fondo: entender qué significa realmente que una red neuronal sea un compresor, qué gana y qué pierde en el proceso, y por qué esa perspectiva cambia la forma en que pensamos sobre el entrenamiento, la generalización y los límites fundamentales de la inteligencia artificial.
Predecir es comprimir
Shannon y la sorpresa medible
En 1948, Claude Shannon publicó “A Mathematical Theory of Communication”, un paper que fundó la teoría de la información. Una de sus ideas más profundas fue que la información no es una cualidad subjetiva sino una cantidad medible, definida en términos de incertidumbre -una línea de pensamiento paralela a la de su contemporáneo John von Neumann en Princeton.
Shannon definió la entropía de una fuente de información como:
donde es la probabilidad de cada símbolo posible. La entropía mide cuántos bits de información en promedio produce cada símbolo de la fuente. Un texto en inglés tiene una entropía de alrededor de 1 a 1.5 bits por carácter -mucho menos que los ~4.7 bits que necesitarías si cada letra fuera igualmente probable. Esa redundancia es lo que hace posible la compresión.
Pero la idea crucial de Shannon fue el teorema de codificación de fuente: el límite inferior teórico para la longitud media de un código sin pérdida es la entropía de la fuente. No podés comprimir un mensaje a menos bits que su entropía sin perder información.
El puente a la predicción
Acá viene el salto conceptual. Para comprimir un símbolo de forma óptima, necesitás asignarle un código de longitud bits, donde es su probabilidad. Pero -¿quién define ? Necesitás un modelo probabilístico de la fuente. Mejor dicho: necesitás un predictor.
Un codificador aritmético, por ejemplo, comprime un mensaje usando las probabilidades que un modelo predictivo le asigna a cada símbolo siguiente. Si el modelo predice bien (asigna alta probabilidad a lo que realmente viene), el código es corto. Si predice mal (asigna alta probabilidad a otra cosa), el código es largo.
Predecir bien = comprimir bien. La misma cosa vista desde dos ángulos.
Entropía cruzada (Cross Entropy): la función que comprime
Las redes neuronales se entrenan minimizando la entropía cruzada (cross-entropy loss). Para un modelo que predice la probabilidad de cada token dado el contexto , la pérdida es:
Esta fórmula es -literalmente- la estimación Monte Carlo de la entropía cruzada entre la distribución real de los datos y la distribución aprendida por el modelo. Y la entropía cruzada tiene una interpretación directa en compresión: es la cantidad de bits por token que necesitarías para codificar los datos si usaras el modelo como esquema de codificación.
Cuando un modelo alcanza una entropía cruzada (cross-entropy) de, digamos, 3.5 bits por token en el conjunto de validación, eso significa que, en el mejor de los casos, podrías comprimir el texto de validación a 3.5 bits por token usando ese modelo como predictor para un codificador aritmético. El límite teórico estaría dado por la entropía real del lenguaje.
Entrenar un modelo de lenguaje es construir un compresor especializado para el lenguaje en el que fue entrenado. La función de pérdida es directamente una medida de la tasa de compresión que ese compresor alcanzaría.
Analogía: pensá en la entropía cruzada (cross-entropy) como la tasa de bits de un códec. Un modelo con entropía cruzada (cross-entropy) de 1.12 bpc (bits por carácter, como los mejores modelos actuales en inglés) representa un compresor que reduce el texto a ~1.12 bits por carácter. El formato UTF-8 sin comprimir usa 8 bits por carácter. La tasa de compresión es de aproximadamente 7:1.
Cómo comprime el entrenamiento
El paisaje de pérdida
Cuando comenzás a entrenar una red neuronal desde pesos aleatorios, el modelo no sabe nada sobre los datos. Su entropía cruzada (cross-entropy) es alta, cercana a la de una distribución uniforme sobre el vocabulario. A medida que el entrenamiento avanza, la pérdida disminuye: el modelo está descubriendo patrones en los datos.
¿Qué son esos patrones? Son regularidades estadísticas: que después de “El gato está sobre la” suele venir “mesa” y no “elefante”; que una imagen con ciertos píxeles claros en el borde superior y oscuros en el inferior suele ser un número 1 escrito a mano; que tal secuencia de muestras de audio correlacionadas corresponde a la vocal /a/.
Cada patrón descubierto es información que pasa de los datos al modelo. Pero el modelo tiene capacidad limitada (cantidad de parámetros), así que no puede guardar todos los patrones -tiene que priorizar. Los patrones más frecuentes, más generales, más estadísticamente robustos se graban en los pesos. Los detalles finos, las excepciones raras, el ruido- se pierden. Esa pérdida es el “con pérdida” de la compresión.
¿Dónde está la información?
Una red neuronal típica tiene millones o miles de millones de parámetros. Un parámetro individual es un número de punto flotante -digamos, FP16 (16 bits) o FP32 (32 bits). La memoria total del modelo es la cantidad de parámetros multiplicada por los bits por parámetro.
Pero el entrenamiento se hizo sobre gigabytes o terabytes de datos. La cantidad de información en los datos de entrenamiento excede por órdenes de magnitud la capacidad de almacenamiento de los pesos. Si los pesos pudieran reconstruir exactamente los datos de entrenamiento, eso sería memorización perfecta -y requeriría al menos tanta capacidad de almacenamiento como los datos originales (por el teorema de Shannon).
Lo que ocurre, entonces, es que la red destila los datos: encuentra una representación compacta que captura la estructura subyacente. Es exactamente lo que hace un códec de audio: no guarda la forma de onda exacta, sino los coeficientes espectrales que permiten reconstruir una aproximación convincente.
| Concepto | Compresión tradicional | Red neuronal |
|---|---|---|
| Entrada | Archivo de audio WAV | 10 TB de texto de internet |
| Salida | Archivo MP3 de 10 MB | Pesos del modelo: 14 GB (LLaMA-70B en FP16) |
| Tasa de compresión | ~100:1 para MP3 a 128kbps | ~700:1 para Chinchilla 70B / entrenamiento |
| Pérdida | Artefactos de compresión | Alucinaciones, errores en colas de distribución |
| Códec | MP3 (diseñado por humanos) | Pesos (aprendidos por optimización) |
No todo se comprime igual
Un hallazgo fascinante de la investigación reciente es que las redes neuronales no comprimen toda la información por igual. Los patrones que aparecen con alta frecuencia en los datos de entrenamiento se codifican de forma mucho más eficiente que los raros. Esto tiene un correlato directo en la teoría de la información: la longitud del código óptimo para un símbolo depende de su probabilidad, y los símbolos raros tienen códigos más largos.
En la práctica, esto significa que un modelo de lenguaje recuerda muy bien los hechos comunes -“París es la capital de Francia”- y lucha con los hechos poco frecuentes -“la capital de Burkina Faso es Uagadugú”. No es que el modelo “no sepa” lo segundo; es que la tasa de compresión asignada a ese hecho es más baja, y por tanto su reconstrucción es más ruidosa. Es la misma razón por la que un MP3 a baja tasa de bits reproduce bien una voz hablada pero hace añicos un platillo de batería: los transientes agudos son información de alta entropía que el códec sacrifica primero.
Qué se pierde
De la alucinación al olvido
Decir que una red neuronal es un compresor con pérdida es plantear inmediatamente la pregunta: ¿qué se pierde? La respuesta es más sutil que en MP3 o JPEG, porque la “calidad perceptiva” no está definida por el oído o el ojo humano sino por la tarea.
En compresión tradicional, la pérdida se mide contra el original: el audio reconstruido vs. el WAV original, la imagen descomprimida vs. el RAW. En las redes neuronales, no hay un “original” que reconstruir -el modelo no guarda los datos, guarda regularidades. La pérdida se manifiesta como:
- Errores de generalización: el modelo no puede predecir correctamente puntos fuera de la distribución de entrenamiento.
- Alucinaciones: en modelos de lenguaje, cuando el modelo genera información plausible pero falsa. Es la marca del compresor con pérdida estirando su representación compacta para cubrir un espacio que no termina de entender.
- Sesgos estadísticos: el modelo amplifica patrones mayoritarios y erosiona minoritarios. No porque sea “discriminador” en un sentido moral, sino porque la compresión con pérdida optimiza para el caso más probable.
- Olvido catastrófico: cuando se entrena en una nueva tarea, el modelo “descomprime” sus pesos para hacer espacio, perdiendo información de la tarea anterior.
Doble caída y grokking
Un descubrimiento contraintuitivo de los últimos años es el fenómeno de double descent (doble caída) y grokking (asimilación repentina). A medida que aumentás el tamaño del modelo, la pérdida en test primero baja, luego sube (el modelo empieza a memorizar ruido), y luego vuelve a bajar cuando el modelo es tan grande que puede generalizar de verdad.
Interpretado desde la compresión: cuando el modelo es pequeño (baja capacidad), comprime agresivamente -generaliza bien pero pierde detalles finos. Cuando el modelo tiene capacidad intermedia, empieza a “memorizar” ejemplos específicos (como un compresor que guarda cada píxel individual en vez de aprovechar patrones), lo que empeora la compresión en términos de tasa de bits efectiva. Cuando el modelo es suficientemente grande, logra un equilibrio: encuentra la representación compacta óptima que captura la estructura sin caer en la memorización.
Este punto óptimo es el que buscan las leyes de escalado (scaling laws) como las de Chinchilla: para un presupuesto de cómputo dado, existe una relación óptima entre cantidad de parámetros y cantidad de datos de entrenamiento que maximiza la compresión.
Dato concreto: según las leyes de escalado de DeepMind (Hoffmann et al., 2022), para el presupuesto de cómputo estudiado la relación óptima fue de aproximadamente 20 tokens de entrenamiento por parámetro -de ahí que Chinchilla 70B se entrenara con ~1.4 billones de tokens (70 mil millones × 20 = 1.400 mil millones = 1,4 billones; en inglés 1.4 trillion). El hallazgo central del paper es que parámetros y tokens deben escalarse en igual proporción: duplicar uno exige duplicar el otro. Los modelos actuales (2026) suelen entrenarse con más tokens que los óptimos de Chinchilla, priorizando la calidad del modelo sobre la eficiencia de cómputo.
Espejos analógicos
MP3: lo que el oído no escucha
El MP3 funciona explotando las limitaciones del sistema auditivo humano. El oído es menos sensible a ciertas frecuencias, especialmente cuando otras frecuencias cercanas son más fuertes (enmascaramiento frecuencial). El códec elimina la información que el oído no va a percibir de todas formas.
La psicoacústica es la ciencia que estudia este fenómeno, y es la base sobre la que se construyen los códecs de audio con pérdida. Una red neuronal hace algo análogo pero su “sistema perceptual” no está dado por la biología sino por la tarea. Durante el entrenamiento, la red aprende qué información es relevante para minimizar su pérdida y qué información es redundante o irrelevante. Los pesos se ajustan para maximizar la retención de la primera y minimizar el “costo” de almacenar la segunda.
| Aspecto | MP3 | Red Neuronal |
|---|---|---|
| Modelo perceptual | Psicoacústica humana | Función de pérdida |
| Qué descarta | Frecuencias enmascaradas | Patrones estadísticamente débiles |
| Artefacto típico | Pre-echo, pérdida de agudos | Alucinaciones, sesgos |
| Tasa de bits ajustable | Sí (calidad seleccionable) | Indirectamente (tamaño del modelo) |
JPEG: de píxeles a frecuencias
JPEG transforma la imagen del dominio espacial al dominio frecuencial (DCT, transformada de coseno discreta), cuantiza los coeficientes (perdiendo información) y luego comprime el resultado. La red neuronal, de forma análoga, transforma los datos de entrada a través de sus capas ocultas (un “espacio latente”), donde representa la información de forma más eficiente.
La analogía es particularmente precisa en los autoencoders: redes entrenadas para reconstruir su entrada después de pasar por un cuello de botella (bottleneck). El espacio latente en el medio es, explícitamente, una representación comprimida. Un autoencoder variacional (VAE) lleva esto al extremo: aprende una distribución de probabilidad sobre el espacio latente, y la pérdida incluye un término de regularización que fuerza a esa distribución a acercarse a una distribución normal estándar -un compresor que no solo empaqueta la información sino que la organiza en una estructura matemática conveniente.
Un compresor que nadie diseñó
La diferencia fundamental entre MP3/JPEG y una red neuronal es que el códec no está diseñado por un humano. En la compresión tradicional, ingenieros analizan las propiedades del sistema perceptual y construyen el algoritmo a mano. En una red neuronal, el algoritmo de compresión emerge del proceso de optimización.
Esto tiene una consecuencia profunda: la compresión neuronal puede descubrir estructuras que los humanos no conocíamos. DeepMind demostró que Chinchilla 70B comprime imágenes mejor que PNG (58.5% vs 43.4%) a pesar de no haber sido entrenado en imágenes -la estructura del lenguaje natural, al ser aprendida, captura regularidades que resultan transferibles a otros dominios. Es como si un compresor de audio, por haber “aprendido” a comprimir sinfonías, resultara también excelente comprimiendo fotos.
Esto desafía la noción misma de que la compresión con pérdida es específica del dominio. Si un modelo entrenado solo en texto comprime imágenes mejor que PNG, entonces los límites entre dominios de información son más porosos de lo que creíamos.
La verificación experimental
El paper de DeepMind
En septiembre de 2023, Grégoire Delétang, Anian Ruoss y colaboradores de Google DeepMind publicaron “Language Modeling Is Compression” -aceptado como presentación oral en ICLR 2024- un trabajo que puso a prueba la equivalencia entre modelos de lenguaje y compresores de datos.
El experimento fue directo: tomaron modelos Chinchilla de distintos tamaños (hasta 70B parámetros) y los usaron como modelos de probabilidad para un codificador aritmético, un esquema de compresión que puede usar cualquier distribución de probabilidad como base. Luego midieron la tasa de compresión alcanzada en tres tipos de datos:
| Dataset | Tipo | Chinchilla 70B | Mejor compresor previo |
|---|---|---|---|
| Enwik9 (texto) | Texto plano | 8.3% del tamaño original | 9.1% (compresores especializados) |
| ImageNet (parches) | Imágenes | 43.4% | 58.5% (PNG) |
| LibriSpeech | Audio | 16.4% | 30.3% (FLAC) |
Los resultados son notables por varias razones:
- Chinchilla 70B superó a todos los compresores previos en los tres dominios.
- Lo hizo a pesar de haber sido entrenado exclusivamente en texto -nunca vio imágenes ni audio durante el entrenamiento.
- La compresión mejoraba con el tamaño del modelo: a más parámetros, mejor compresión, incluso en dominios fuera de texto.
Por qué el contexto importa
El paper también demostró que estos modelos logran su capacidad compresora gracias al contexto. Cuando se les da un pequeño fragmento del archivo a comprimir (in-context learning), el modelo se adapta rápidamente a las propiedades estadísticas de ese tipo de datos. Es como si el compresor “olfateara” el archivo antes de comprimirlo para ajustar sus parámetros internos -un comportamiento que los códecs tradicionales no tienen.
Esto sugiere que los modelos de lenguaje no son solo compresores genéricos: son meta-compresores que pueden especializarse sobre la marcha según el contexto.
Un hallazgo complementario llegó en 2024 con el trabajo de Butakov et al. (“Information Bottleneck Analysis of Deep Neural Networks via Lossy Compression”, también en ICLR 2024). Usando redes neuronales estocásticas para comprimir representaciones intermedias, demostraron que el fenómeno de compresión predicho por Tishby -donde la información mutua entre capas ocultas y la entrada disminuye durante el entrenamiento- es observable incluso en redes profundas a escala real, no solo en “toy models”. La compresión no es una metáfora: es un proceso medible que ocurre dentro de la red durante el entrenamiento.
La sorpresa
Hay un dato que relativiza estos resultados: los modelos de DeepMind fueron entrenados en datos que incluyen Wikipedia y libros. Enwik9 es un subconjunto de Wikipedia (los primeros 10^9 bytes). Es posible que parte de la capacidad compresora provenga de haber visto fragmentos de los mismos textos durante el entrenamiento.
Sin embargo, el hecho de que la compresión funcione igualmente bien en ImageNet (imágenes) y LibriSpeech (audio), que con seguridad no estaban en los datos de entrenamiento, sugiere que el fenómeno es genuino. El modelo no está “recordando” los datos originales (no podría, con 70B parámetros no hay suficiente capacidad para guardar 10^9 bytes de texto). Está capturando regularidades profundas que trascienden el dominio textual.
El techo de cristal
Lo que Shannon no permite
Si las redes neuronales son compresores con pérdida, están sujetas a los mismos límites fundamentales que cualquier compresor. El más importante: no se puede comprimir más allá de la entropía de la fuente.
Para el lenguaje natural, la entropía se estima en alrededor de 1-1.5 bits por carácter en inglés. Los mejores modelos actuales están cerca de 1.12 bpc (bits per character). Eso significa que el margen de mejora es pequeño -quizás un factor de 2 como máximo desde donde estamos hoy.
Esto tiene una implicación explosiva: si los modelos de lenguaje son compresores y estamos cerca del límite de Shannon, entonces los grandes saltos en calidad que vimos en los últimos años (GPT-3 → GPT-4 → GPT-5) no pueden continuar indefinidamente. Cada mejora adicional cuesta más cómputo y produce menos ganancia. Es ley de rendimientos decrecientes escrita en la teoría de la información.
Comprimir sin memorizar
Un compresor con pérdida perfecto para los datos de entrenamiento no es necesariamente un buen generalizador. De hecho, la compresión sin pérdida de los datos de entrenamiento sería memorización, y sabemos que los modelos que memorizan no generalizan bien.
Esto plantea una paradoja: el modelo ideal no es el que mejor comprime los datos de entrenamiento, sino el que mejor comprime la distribución subyacente. Pero la distribución subyacente no es observable directamente -solo tenemos muestras. El modelo debe comprimir las muestras sin caer en sobreadaptación (overfitting).
Las técnicas de regularización (dropout, weight decay, data augmentation) son, desde esta perspectiva, mecanismos para forzar al compresor a priorizar la estructura general sobre el ruido específico. Son la contraparte de los filtros de suavizado en un codificador de imagen: sacrifican fidelidad en los detalles a cambio de una representación más robusta.
Implicaciones
¿La inteligencia es compresión?
Esta es, para mí, la pregunta más profunda que plantea esta línea de pensamiento. Si la capacidad de predecir -y por tanto comprimir- es la base del aprendizaje, y las redes neuronales más avanzadas son simplemente compresores muy eficientes, entonces ¿hay alguna diferencia cualitativa entre comprimir y entender?
Una posición extrema (defendida por algunos investigadores como Ilya Sutskever en sus primeros escritos) es que no: que “entender” es tener un modelo predictivo del mundo, y que tener un modelo predictivo del mundo es tener una representación comprimida de sus regularidades. Desde esta óptica, un LLM que predice la siguiente palabra está haciendo exactamente lo mismo que un científico que predice el resultado de un experimento: ambos están usando un modelo interno comprimido para anticipar la realidad.
No termino de inclinarme por ninguna de las dos. Me parece que la compresión con pérdida, por definición, sacrifica información, y si la inteligencia requiere retener información crucial aunque sea rara -el hecho inusual, la excepción a la regla, la sutileza- entonces un compresor que optimiza para el caso promedio está condenado a perder justamente lo que hace valiosa a la inteligencia. Pero también me parece que subestimar el poder de un buen compresor es un error: la historia de la ciencia es, en buena medida, la historia de encontrar representaciones cada vez más compactas de la realidad.
El tamaño importa, hasta cierto punto
La relación entre capacidad del modelo y calidad de la compresión tiene implicaciones prácticas. Las leyes de escalado de Kaplan et al. (2020) mostraron que la pérdida sigue una ley de potencia respecto del tamaño del modelo: duplicar la cantidad de parámetros reduce la cross-entropy aproximadamente un 5%, no un 50%. La mejora es real pero decreciente -cada nuevo salto cuesta más y rinde menos.
El costo energético escala en proporción. Entrenar un modelo frontera como GPT-4 insume entre 50 y 60 gigavatios-hora (GWh), suficiente para abastecer miles de hogares durante un año. La pregunta inevitable es: ¿vale la pena gastar ese presupuesto energético para reducir la perplejidad de 1.2 a 1.15 bits por carácter, una ganancia que probablemente ningún usuario notaría en una conversación cotidiana? Es el dilema del rendimiento decreciente aplicado a la compresión neuronal: cada bit adicional de compresión cuesta exponencialmente más energía.
La dirección de la industria en 2026 confirma esta intuición. Arquitecturas como la de DeepSeek V3 -que con 671 mil millones de parámetros totales solo activa 37 mil millones por token gracias a su diseño de mezcla de expertos (MoE)- o modelos como Llama 4 Scout (17B parámetros) logran eficiencia por dólar de inferencia muy superior a la de sus predecesores directos. Esto no contradice la tesis de la compresión: confirma que la ingeniería de arquitecturas y la calidad de los datos pueden mejorar la tasa de compresión sin aumentar el tamaño efectivo del compresor.
Los sesgos son compresión
Si un modelo de lenguaje es un compresor con pérdida del texto en el que fue entrenado, entonces sus “valores” no son más que regularidades estadísticas comprimidas. El sesgo de género, los prejuicios culturales, las preferencias políticas -todo eso está codificado en los pesos como parte del proceso de compresión.
Esto es a la vez una limitación y una oportunidad. Es una limitación porque significa que los sesgos no son un bug sino una característica inevitable de la compresión con pérdida: al priorizar patrones frecuentes, el compresor amplifica mayorías. Es una oportunidad porque el marco teórico de la compresión ofrece herramientas para medir, cuantificar y quizás corregir estos sesgos de forma más rigurosa que las aproximaciones actuales.
Epílogo
La idea de que entrenar una red neuronal es construir un compresor con pérdida me parece elegante porque unifica fenómenos que parecían dispares:
- Por qué los modelos más grandes funcionan mejor: porque un compresor con más capacidad puede almacenar más regularidades.
- Por qué más datos ayudan hasta cierto punto: porque el compresor necesita suficientes ejemplos para distinguir el patrón del ruido.
- Por qué los modelos alucinan: la compresión con pérdida descarta detalles que considera estadísticamente irrelevantes. Cuando el modelo necesita esos detalles -un nombre, una fecha, una excepción a la regla- no tiene dónde recuperarlos. Pero como su tarea es generar, no puede responder “no sé”: está entrenado para predecir la continuación más probable. El hueco se rellena con lo que mejor encaja en la distribución aprendida. Es el equivalente textual de un artefacto de compresión: donde JPEG pierde los agudos de un platillo, el modelo pierde el hecho raro y lo reemplaza con uno plausible. Investigaciones recientes (Xu et al. (2024)) demuestran que este fenómeno no es un defecto corregible sino una consecuencia inevitable de la capacidad finita de información: para cualquier modelo, existe al menos un dato que será distorsionado al ser comprimido.
- Por qué el fine-tuning funciona: porque estás ajustando un compresor genérico a un dominio específico, exactamente como un códec que se especializa.
- Por qué los transformers superaron a las RNN: porque la atención permite al compresor acceder directamente al contexto relevante sin el cuello de botella de un estado oculto comprimido.
A mí lo que más me queda resonando es esto: los 671 mil millones de parámetros de DeepSeek V3 no almacenan conocimiento en el sentido humano. Almacenan la huella que dejaron los datos al ser aplastados contra una función de pérdida. Lo que llamamos “inteligencia” es, visto de cerca, estadística comprimida.
O, para decirlo con Shannon: si la inteligencia es predicción, y predecir bien es asignar alta probabilidad a lo que realmente ocurre, entonces el modelo más inteligente es simplemente el que mejor comprime. Un código que le ahorra bits a lo probable y se los cobra caros a lo improbable. Nada más que eso.
Referencias
- Shannon, C. E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal.
- Delétang, G., Ruoss, A., et al. (2023). Language Modeling Is Compression. DeepMind. ICLR 2024.
- Tishby, N., Zaslavsky, N. (2015). Deep Learning and the Information Bottleneck Principle. IEEE Information Theory Workshop.
- Hoffmann, J., Borgeaud, S., et al. (2022). Training Compute-Optimal Large Language Models. (Chinchilla scaling laws).
- Cover, T. M., Thomas, J. A. (2006). Elements of Information Theory. 2nd ed. Wiley.
- Hinton, G. E., Salakhutdinov, R. R. (2006). Reducing the Dimensionality of Data with Neural Networks. Science, 313(5786).
- Shannon, C. E. (1951). Prediction and Entropy of Printed English. Bell System Technical Journal.
- Belkin, M., et al. (2019). Reconciling modern machine-learning practice and the classical bias-variance trade-off. PNAS.
- Power, A., et al. (2022). Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets.
- Butakov, I., Tolmachev, A. D., et al. (2024). Information Bottleneck Analysis of Deep Neural Networks via Lossy Compression. ICLR 2024.
- Xu, Z., Jain, S., Kankanhalli, M. (2024). Hallucination is Inevitable: An Innate Limitation of Large Language Models.